@inproceedings{jin2026mergemix,title={MergeMix: A Unified Augmentation Paradigm for Visual and Multi-Modal Understanding},author={Jin, Xin and Li, Siyuan and Jian, Siyong and Yu, Kai and Wang, Huan},booktitle={ICLR},year={2026},}
ICLR
OBS-Diff: Accurate Pruning For Diffusion Models in One-Shot
@inproceedings{zhu2026obsdiff,title={OBS-Diff: Accurate Pruning For Diffusion Models in One-Shot},author={Zhu, Junhan and Wang, Hesong and Su, Mingluo and Wang, Zefang and Wang, Huan},booktitle={ICLR},year={2026},}
ICLR
RewardMap: Tackling Sparse Rewards in Fine-grained Visual Reasoning via Multi-Stage Reinforcement Learning
@inproceedings{feng2026rewardmap,title={RewardMap: Tackling Sparse Rewards in Fine-grained Visual Reasoning via Multi-Stage Reinforcement Learning},author={Feng, Sicheng and Tuo, Kaiwen and Wang, Song and Kong, Lingdong and Zhu, Jianke and Wang, Huan},booktitle={ICLR},year={2026},}
ICLR
Autoregressive Image Generation with Randomized Parallel Decoding
@inproceedings{li2026arpg,title={Autoregressive Image Generation with Randomized Parallel Decoding},author={Li, Haopeng and Yang, Jinyue and Li, Guoqi and Wang, Huan},booktitle={ICLR},year={2026},}
2025
arXiv
OmniZip: Audio-Guided Dynamic Token Compression for Fast Omnimodal Large Language Models
@article{tao2025omnizip,title={OmniZip: Audio-Guided Dynamic Token Compression for Fast Omnimodal Large Language Models},author={Tao, Keda and Shao, Kele and Yu, Bohan and Wang, Weiqiang and Liu, Jian and Wang, Huan},journal={arXiv preprint arXiv:2511.14582},year={2025},}
arXiv
StreamingTOM: Streaming Token Compression for Efficient Video Understanding
@article{chen2025streamingom,title={StreamingTOM: Streaming Token Compression for Efficient Video Understanding},author={Chen, Xueyi and Tao, Keda and Shao, Kele and Wang, Huan},journal={arXiv preprint arXiv:2510.18269},year={2025},}
arXiv
Which Heads Matter for Reasoning? RL-Guided KV Cache Compression
@article{du2025rlkv,title={Which Heads Matter for Reasoning? RL-Guided KV Cache Compression},author={Du, Wenjie and Jiang, Li and Tao, Keda and Liu, Xue and Wang, Huan},journal={arXiv preprint arXiv:2510.08525},year={2025},}
arXiv
When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and Audios
@article{shao2025tokens,title={When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and Audios},author={Shao, Kele and Tao, Keda and Zhang, Kejia and Feng, Sicheng and Cai, Mu and Shang, Yuzhang and You, Haoxuan and Qin, Can and Sui, Yang and Wang, Huan},journal={arXiv preprint arXiv:2507.20198},year={2025},database={https://oasis-paddleboat-fc1.notion.site/when-tokens-talk-too-much-database},paper_repo={https://github.com/cokeshao/Awesome-Multimodal-Token-Compression},}
arXiv
SparseSSM: Efficient Selective Structured State Space Models Can Be Pruned in One-Shot
@article{tuo2025sparsessm,title={SparseSSM: Efficient Selective Structured State Space Models Can Be Pruned in One-Shot},author={Tuo, Kaiwen and Wang, Huan},journal={arXiv preprint arXiv:2506.09613},year={2025},}
arXiv
ResSVD: Residual Compensated SVD for Large Language Model Compression
@article{bai2025ressvd,title={ResSVD: Residual Compensated SVD for Large Language Model Compression},author={Bai, Haolei and Jian, Siyong and Liang, Tuo and Yin, Yu and Wang, Huan},journal={arXiv preprint arXiv:2505.20112},year={2025},}
arXiv
Can MLLMs Guide Me Home? A Benchmark Study on Fine-Grained Visual Reasoning from Transit Maps
Sicheng Feng , Song Wang, Shuyi Ouyang, Lingdong Kong, Zikai Song , Jianke Zhu, Huan Wang , and Xinchao Wang
@article{feng2025canmllms,title={Can MLLMs Guide Me Home? A Benchmark Study on Fine-Grained Visual Reasoning from Transit Maps},author={Feng, Sicheng and Wang, Song and Ouyang, Shuyi and Kong, Lingdong and Song, Zikai and Zhu, Jianke and Wang, Huan and Wang, Xinchao},journal={arXiv preprint arXiv:2505.18675},year={2025},dataset={https://huggingface.co/datasets/FSCCS/ReasonMap},qbitai={https://mp.weixin.qq.com/s/sPJLQtHgl5DZghWLWa_H3Q},}
arXiv
Plug-and-Play 1.x-Bit KV Cache Quantization for Video Large Language Models
@article{tao2025plugandplay,title={Plug-and-Play 1.x-Bit KV Cache Quantization for Video Large Language Models},author={Tao, Keda and You, Haoxuan and Sui, Yang and Qin, Can and Wang, Huan},journal={arXiv preprint arXiv:2503.16257},year={2025},}
NeurIPS
HoliTom: Holistic Token Merging for Fast Video Large Language Models
@inproceedings{shao2025holitom,title={HoliTom: Holistic Token Merging for Fast Video Large Language Models},author={Shao, Kele and Tao, Keda and Qin, Can and You, Haoxuan and Sui, Yang and Wang, Huan},booktitle={NeurIPS},year={2025},}
NeurIPS
FreqExit: Enabling Early-Exit Inference for Visual Autoregressive Models via Frequency-Aware Guidance
@inproceedings{li2025freqexit,title={FreqExit: Enabling Early-Exit Inference for Visual Autoregressive Models via Frequency-Aware Guidance},author={Li, Ying and Lv, Chengfei and Wang, Huan},booktitle={NeurIPS},year={2025},}
CVPR
DyCoke: Dynamic Compression of Tokens for Fast Video Large Language Models
@inproceedings{tao2025dycoke,title={DyCoke: Dynamic Compression of Tokens for Fast Video Large Language Models},author={Tao, Keda and Qin, Can and You, Haoxuan and Sui, Yang and Wang, Huan},booktitle={CVPR},year={2025},}
ICCV
On-Device Diffusion Transformer Policy for Efficient Robot Manipulation
Yiming Wu, Huan Wang , Zhenghao Chen, Jianxin Pang , and Dong Xu
@inproceedings{wu2025ondevice,title={On-Device Diffusion Transformer Policy for Efficient Robot Manipulation},author={Wu, Yiming and Wang, Huan and Chen, Zhenghao and Pang, Jianxin and Xu, Dong},booktitle={ICCV},year={2025},}
ACM MM
Individual Content and Motion Dynamics Preserved Pruning for Video Diffusion Models
Yiming Wu , Zhenghao Chen, Huan Wang , and Dong Xu
@inproceedings{wu2025videopruning,title={Individual Content and Motion Dynamics Preserved Pruning for Video Diffusion Models},author={Wu, Yiming and Chen, Zhenghao and Wang, Huan and Xu, Dong},booktitle={ACM MM},year={2025},}
TCSVT
Niagara: Normal-Integrated Geometric Affine Field for Scene Reconstruction from a Single View
@article{wu2025niagara,title={Niagara: Normal-Integrated Geometric Affine Field for Scene Reconstruction from a Single View},author={Wu, Xianzu and Ai, Zhenxin and Yang, Harry and Lim, Ser-Nam and Liu, Jun and Wang, Huan},journal={IEEE Transactions on Circuits and Systems for Video Technology},year={2025},}
@article{feng2024oracle,title={Is Oracle Pruning the True Oracle?},author={Feng, Sicheng and Tao, Keda and Wang, Huan},journal={arXiv preprint arXiv:2412.00143},year={2024},}
ECCV Oral
A Simple Low-bit Quantization Framework for Video Snapshot Compressive Imaging
@inproceedings{cao2024simple,title={A Simple Low-bit Quantization Framework for Video Snapshot Compressive Imaging},author={Cao, Miao and Wang, Lishun and Wang, Huan and Yuan, Xin},booktitle={ECCV},year={2024},}
ACM MM
Towards Real-time Video Compressive Sensing on Mobile Devices
@inproceedings{cao2024towards,title={Towards Real-time Video Compressive Sensing on Mobile Devices},author={Cao, Miao and Wang, Lishun and Wang, Huan and Wang, Guoqing and Yuan, Xin},booktitle={ACM MM},year={2024},}




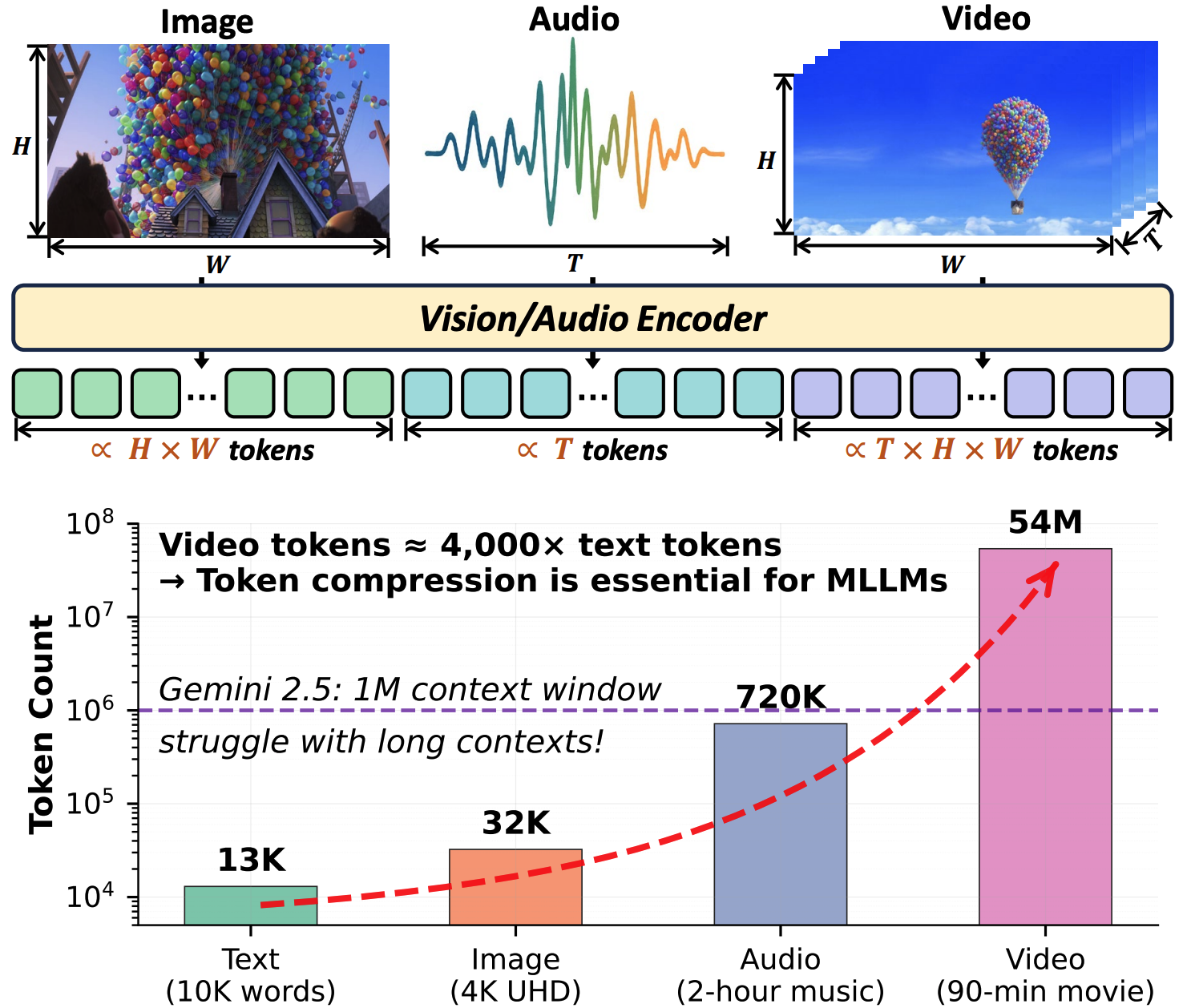 When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and AudiosarXiv preprint arXiv:2507.20198, 2025
When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and AudiosarXiv preprint arXiv:2507.20198, 2025















